

Discover a hybrid information retrieval approach combining vector search and deterministic queries to ensure absolute accuracy on structured data, such as Excel tables, while preserving the power of LLMs.
Introduction
Retrieval-Augmented Generation (RAG) has become the default pattern for talking with corporate documentation through large-language-models (LLM). Most public examples focus on unstructured documents (PDF, HTML, Markdown) - where embeddings + vector similarity search shine. But the moment we work with highly structured data such as Excel or CSV tables, the standard seams to be not helpful:
- Semantic collapse: adjacent rows differ by tiny lexical changes.
- Embedding swamping: nearest-neighbor search (cosine distances) returns “almost the same” row, not necessarily the exact one.
- Numbers blur in embedding space: to the model, “120 mm” and “130 mm” can look almost identical, so queries that rely on exact diameters may drift to the wrong row.
In compliance-oriented environments (chemical piping, aerospace part matching, medical dosages, …) almost correct is absolutely wrong. This article proposes and evaluates a hybrid retrieval stack that couples a classic No-SQL data storing with a lightweight LLM-intent detector, delegating Excel queries to deterministic look-ups while preserving RAG for genuinely unstructured passages.
Why vector-only fails on repetitive tables
Consider the miniature compatibility matrix below (CSV format for brevity).
Pipe-A | Pipe-B |
100 mm | 100 mm |
100 mm | 120 mm |
100 mm | 130 mm |
120 mm | 120 mm |
120 mm | 130 mm |
The “one-sentence-per-row” strategy converts each line into a natural-language chunk, as follows (example for the second row):
“A Pipe-A of 100 mm diameter is compatible with a Pipe-B of 120 mm diameter.”
Feed those five snippets into an embedding model (e.g. text-embedding-3-large or multilingual-e5-large) and you obtain five vectors that differ mostly in two token positions. In practice, the sentence embeddings are over 95 % alike, so the model can’t tell one row from another. A typical top-k (k = 3) retrieval therefore cannot guarantee that the numerically exact row surfaces; the wrong 130 mm pairing may rank above the true 120 mm entry simply because of sub-token rounding or float representation.
Fine-tuning embeddings on synthetically generated numeric paraphrases helps a little, but the cost-benefit ratio is unattractive when:
- the table is very small (a few hundreds of rows);
- numeric precision is mandatory;
- latency must stay under 100 ms.
The hybrid retrieval pattern
A classic RAG pipeline has three hops:
- Embedding: All text fragments (PDF paragraphs, HTML blocks, and table rows) are turned into dense vectors.
- Similarity search: The user question is embedded, and vector search retrieve the “closest” vectors (most relevant data).
- Generation: The retrieved content is injected into the LLM together with the question, and it produces an answer.
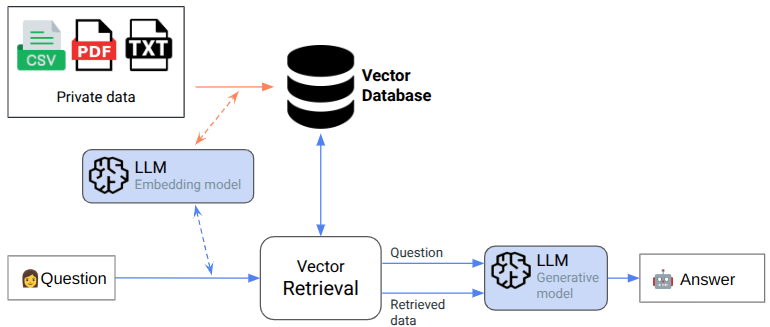
That works beautifully for prose, but fails for the millimetre-level precision of engineering tables.
The hybrid pattern splits responsibilities, instead of forcing every data type through the same vector gate:
Tabular data storing
The information in tabular files is stored in structured databases. In our particular use-case, the volume of the information to use was very small (few hundreds of lines), so our choice pointed to a Cache for Redis, so the data is loaded in memory, facilitating the access and reducing the latency to the minimum.
Intent and slot extraction
By using small LLMs + system prompt (few-shot), this layer is responsible for the extraction of the user intent, and the related parameters (slots): does the user ask “Are X and Y compatible?” and if so, what are the values?
Deterministic lookup
If the slots are sents, we fetch the exact data from the database and convert the canonical row into human-readable sentence(s), to be merged with regular RAG context.
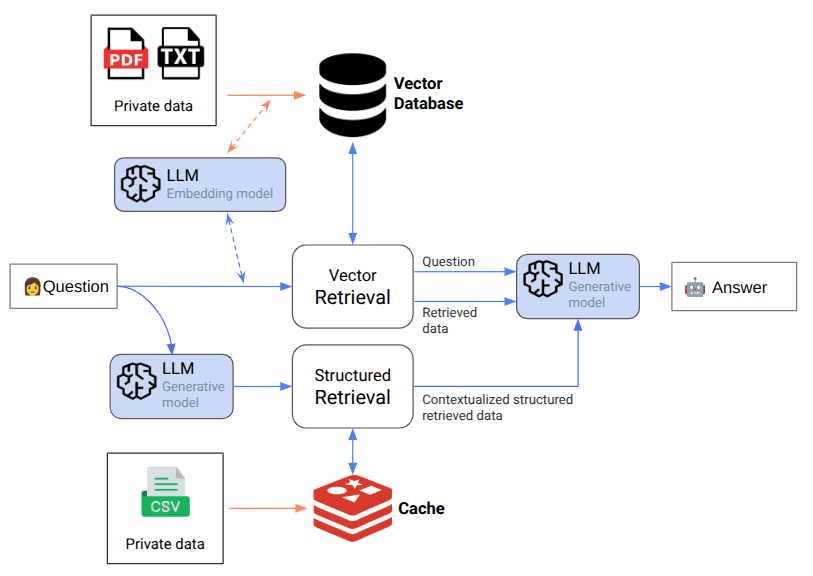
In this article, we don’t discuss some edge-cases that we treat (like answering “unknown” the compatibility pair is not found, and others) in order to keep light.
Key design choices
- Memory first: Cache for Redis caches the whole sheet (< 1 MB) in RAM, reducing latency (median latency around 1 ms within the same Azure region).
- Stateless inference: The intent-LLM is called only to extract the user intent and slots. It can be light-weight, and vendor cost is minimal (< 200 input tokens). Few-shot prompt fits in less than 200 tokens, and using light-weight models like gpt-3.5-turbo keeps cost below $0.0004 per call.
- No changes to the RAG pipeline: Document retrieval (vector search over PDFs) remains untouched. The pipe-compatibility sentence is injected into the system/context prompt, so hallucination risk stays low. If the DB is unavailable, the system redirects the chatbot to the “I’m not sure, here’s what the manuals say…” answer, through the RAG. No single point of failure for the rest of the knowledge base.
Advantages
- Zero hallucination on tabular facts: numeric truth is fetched, not inferred.
- Explainability: we can log the exact row that backed a sentence.
- Isolation of concerns: the main RAG chain remains language-centric; structured data lives elsewhere.
- Elasticity/Modularity: swapping Redis for Cosmos DB or DynamoDB is trivial for larger sheets.
Conclusion
Vector search is unbeatable for fuzzy semantic recall, but it weakens wherever exact numeric matches determine truth. By introducing a thin layer that detects intent, extracts numeric slots, hits an in-memory key- value store, and injects the deterministic fact back into the RAG prompt, we obtain a best-of-both-worlds system: deterministic accuracy for structured data and rich generative reasoning for prose.
The engineering overhead is minimal, the runtime cost is negligible, and the payoff - zero hallucinations on critical specifications - is substantial.
